統計学入門(番外編)統計学を勉強してみたところ・・・

Nラボ備忘録は3人で運営していますが、忙しい時期でなかなか更新ができていません。 時間がないということはないですが、やはり心に余裕がないとブログって更新できませんよね。 でもそのぐらい気楽にやるのがいいですよね。
さて本題ですが、私は統計学を独学でちまちま勉強しています。そんな中で統計学を勉強してみて思ったことを一言二言書いてみました。
統計学を勉強して意味あった?
今のところは・・・ないですね・・・頭使うので、頭の体操にはなっています。 もちろん私の仕事内容的に本格的には使わないということであって、統計学が意味ないとは全く思っていないです。 むしろ勉強すればするほど世の中でとても役に立っているのだと実感します。
いつか役に立てば儲けもん程度に思っています。
統計学の勉強はまだやるの?
やります。というかやっています。段々と統計学の深淵に進んでいることを実感しています。誰かに蘊蓄を語って自慢できる程度になれればいいかなと思っています。最後に
このブログはなかなかマイナーかつ大した内容を書いていないので、読者の方は少ない(というかいない?汗)とは思いますが、 これからも細々と続けていくつもりです。夢のまた夢ですが、このブログを見て「統計学か。勉強してみようかな。」と一瞬でも思ってもらえれば嬉しいです。 そのためには更新頻度と質を上げていかないといけないですね。リンク
リンク
※Amazonのアソシエイトとして、当メディア(Nラボ備忘録)は適格販売により収入を得ています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
統計学入門⑫ 回帰分析(1)
(はじめに)
今まであまり計算では文字式を使わないようにしてきましたが、計算が複雑になってきたので使う場合が増えてくると思います。今更ではありますが、データの変数は$\ x\ $や$\ y\ $、平均値は$\ \bar{x}\ $, $\ \bar{y}\ $、標準偏差は$\ s_{x}\ $, $\ s_{y}\ $、分散は$\ {s_{x}}^2\ $, $\ {s_{y}}^2\ $、共分散は$\ s_{xy}\ $、相関係数は$\ r\ $を使っていきます。その他、新しく出てくるものは都度紹介します。
また当記事のテーマ、趣旨については以下の記事をご覧いただければと思います。
今回は話を変えて、$\ $回帰分析$\ $について学び始めようと思います。と言ってもいつも通り初歩的なところだけですが。
回帰分析とは、(簡単に言えば)2つの変数$\ x\ $、$\ y\ $の間に何らかの関係があると考えたときに $\ x\ $から$\ y\ $を予測することです。このとき$\ x\ $を 説明変数 、$\ y\ $を 被説明変数(目的変数) といいます。$\ x\ $は「$\ y\ $を説明する変数」で、$\ y\ $は「$\ x\ $によって説明される変数」ということになります。
ここで言っている「何らかの関係」について、あるアイスクリーム店の「1ヶ月間の売り上げ」と「その月の最高気温」の関係を具体例にして考えていきます。
下の表は1〜12月まで最高気温と売り上げをまとめた表です。ただし、10月の売り上げに関してはデータを消去してしまいました(という設定にしておきます)。
続いて横軸を月毎の最高気温$\ x\ $、縦軸を月毎の売り上げ$\ y\ $としてグラフを書いてみます。
$
y = \alpha + \beta x
$
で表せることができると考えられます。この直線のことを 回帰直線 といいます。 また$\ \alpha\ $と$\ \beta\ $を 回帰係数 といいます。
それでは、ここまでの復習として問題を解いていきます。
下の文章中の($\ $)に当てはまる言葉を考えてみましょう。
2つの変数$\ x\ $と$\ y\ $が何らかの関係を持つと考えたとき、$\ x\ $から$\ y\ $の値を予測することを(ア)という。 ここで$\ x\ $は(イ)、$\ y\ $は(ウ)と呼ばれる。
$\ x\ $と$\ y\ $の関係が直線の式$\ y=\alpha + \beta x\ $で表せるとき、この直線を(エ)という。 ここで、$\ \alpha\ $と$\ \beta\ $を(オ)という。
次回は、回帰係数$\ \alpha\ $と$\ \beta\ $の推定値$\ \hat{\alpha}\ $と$\ \hat{\beta}\ $の求め方を学んでいきます。
最近色々とやりたいことがあって更新が遅いので、いつになるかわかりませんが・・・。
ちなみにですが、私はこちらの参考書で勉強しています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
今まであまり計算では文字式を使わないようにしてきましたが、計算が複雑になってきたので使う場合が増えてくると思います。今更ではありますが、データの変数は$\ x\ $や$\ y\ $、平均値は$\ \bar{x}\ $, $\ \bar{y}\ $、標準偏差は$\ s_{x}\ $, $\ s_{y}\ $、分散は$\ {s_{x}}^2\ $, $\ {s_{y}}^2\ $、共分散は$\ s_{xy}\ $、相関係数は$\ r\ $を使っていきます。その他、新しく出てくるものは都度紹介します。
また当記事のテーマ、趣旨については以下の記事をご覧いただければと思います。

今回は話を変えて、$\ $回帰分析$\ $について学び始めようと思います。と言ってもいつも通り初歩的なところだけですが。
回帰分析とは、(簡単に言えば)2つの変数$\ x\ $、$\ y\ $の間に何らかの関係があると考えたときに $\ x\ $から$\ y\ $を予測することです。このとき$\ x\ $を 説明変数 、$\ y\ $を 被説明変数(目的変数) といいます。$\ x\ $は「$\ y\ $を説明する変数」で、$\ y\ $は「$\ x\ $によって説明される変数」ということになります。
ここで言っている「何らかの関係」について、あるアイスクリーム店の「1ヶ月間の売り上げ」と「その月の最高気温」の関係を具体例にして考えていきます。
下の表は1〜12月まで最高気温と売り上げをまとめた表です。ただし、10月の売り上げに関してはデータを消去してしまいました(という設定にしておきます)。
| 月 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 最高気温 (℃) | 12 | 13 | 15 | 18 | 25 | 28 | 33 | 30 | 27 | 23 | 18 | 14 |
| 売り上げ (万円) | 30 | 32 | 35 | 40 | 50 | 60 | 75 | 65 | 55 | ? | 36 | 30 |

で表せることができると考えられます。この直線のことを 回帰直線 といいます。 また$\ \alpha\ $と$\ \beta\ $を 回帰係数 といいます。
それでは、ここまでの復習として問題を解いていきます。
Exercise1-11
下の文章中の($\ $)に当てはまる言葉を考えてみましょう。
2つの変数$\ x\ $と$\ y\ $が何らかの関係を持つと考えたとき、$\ x\ $から$\ y\ $の値を予測することを(ア)という。 ここで$\ x\ $は(イ)、$\ y\ $は(ウ)と呼ばれる。
$\ x\ $と$\ y\ $の関係が直線の式$\ y=\alpha + \beta x\ $で表せるとき、この直線を(エ)という。 ここで、$\ \alpha\ $と$\ \beta\ $を(オ)という。
次回は、回帰係数$\ \alpha\ $と$\ \beta\ $の推定値$\ \hat{\alpha}\ $と$\ \hat{\beta}\ $の求め方を学んでいきます。
最近色々とやりたいことがあって更新が遅いので、いつになるかわかりませんが・・・。
ちなみにですが、私はこちらの参考書で勉強しています。
リンク
リンク
※Amazonのアソシエイトとして、当メディア(Nラボ備忘録)は適格販売により収入を得ています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
基本情報技術者試験に受かった話【備忘録-基本情報技術者試験対策 #15.5】

少しでも参考になれば嬉しいです。
はじめに
さて、今回は題名の通り、基本情報技術者試験に合格することができたので、そのことについてお話しておきます。仕事終わりにコツコツと勉強を続け、なんとか基本情報に合格することができました。
まずは一安心です。
せっかくなので、午前試験・午後試験に向けてどのように勉強をしていったか、何を対策しておいたかについてまとめておこうと思います。
試験対策の参考にでもしてもらえると嬉しいです!
午前試験の話
まずは、午前試験についてです。正直言うと、午前試験は特に特別な対策をしたわけではありません。
とりあえず初めに参考書を1冊買いました。
これは私が基本情報に関する記事を投稿する際、一緒にオススメしている本です。
漫画形式で読みやすく知識がまとめられているので、私はこの1冊を読み込めば十分だと思います。
リンク
あとはひらすらに過去問を解きまくっていました。
ここで私のオススメとしては、とにかく分かんなくてもいいからまずは過去問を解きまくってみろ!ということです。
最初は全く分かりません。それはしょうがないです。
それでもとにかく解いてみて、分からない箇所にぶつかったらその都度参考書で知識を補填する。
このサイクルが最も効率的だと私は思います。
あとは試験当日までどうやって勉強のモチベーションを保つかですよね。
これは人それぞれあるので、自分に合ったやり方を取ってもらえればいいと思います。
毎日決まった時間に勉強するも良し、何か目標を設定し、達成したら自分にご褒美をあげるも良しです。
とにかく継続して勉強し続けるのが重要だと思います。
ちなみに私の場合は、仕事終わりに毎日午前試験をランダムに20問解く、というのを継続していました。
もちろん勉強し始めは、1問解くごとに分からない箇所を参考書で補填する必要があるので、いきなり20問も解こうとしたらしんどいと思います。
その場合は自分がしんどくない問題数まで落としてあげればいいだけです。
毎日10問とか、毎日5問とかでも全然良いと思います。とにかく続けることが大切です。
そのうちだんだんと慣れてきて、1問1分くらいで解けるようになります。
毎日20問解いても20分ですね。そのくらいなら仕事終わりでも続けられます。
無理のない範囲で、コツコツと勉強をし続けましょう!大切なのは継続ですよ。
午後試験の話
さて、次に午後試験のお話ですね。実は恥ずかしい話、午前試験の過去問ばかりを解きまくっていて、直前まで午後試験の対策を全くしていませんでした・・・
実際、初めて午後試験の過去問を解いてみたのが試験の2~3か月くらい前だったと思います。
いやー、そのときは全く解けなくて正直焦りました・・・
とりあえず試験まで時間もなかったので、午後試験でも点の取りやすい問題だけ重点的に対策し、それ以外は選択しない方針で勉強を進めました。
問1
まず問1の「情報セキュリティ」ですが、これは必須回答問題なので、必ず1回は過去問に触っておきましょう。ただ、正直午前試験の対策をやってれば、難しくないのかなと思います。
私は数回過去問を解いてみて、午前試験の対策やってれば大丈夫だ~、と思ったので、特に問1は重点をおきませんでした。
問われている内容は、午前試験でよく出てくる話がほとんどだと思いますので、午前試験の対策だけしっかりしておきましょう。
(ただし、1回くらいは過去問に触れましょうね。)
問2~5
問2~5は選択形式の問題です。ここで何を選択するのかが重要ですね。問題の選択形式としては、4問の中から2問を選択して回答します。また、この4問も全8問??の中からランダムで出題されます。
すなわち、2問選べば良いからといって、2問だけ対策をしているのでは不十分というわけです。
5問くらいは対策しておいた方がいいんじゃないかな~って思います。
正直人それぞれ解きやすい問題があると思いますので、まずは自分で過去問に触れてみて決めるのが一番です。
少し投げやりな気もしますが、こればかりは仕方ないですね。まずは過去問に触れてみてください。
その中でも、私が選んだ問題を紹介しておきますね。
ソフトウェア・ハードウェア
これはめちゃくちゃ簡単でした。オススメです。この問題も、とにかく午前試験の対策をしていれば楽に解けるものになっています。
追加で対策をしなくていい分、試験に合格するためだけならこれを選択しておくのが無難かなと思います。
データベース
データベースは少し難しいかなと思います。私は自分の肌感的に合っていると感じたので少し対策をしましたが、合わない人もいるとは思います。
絶対オススメ!というわけではありません・・・
プロジェクトマネジメント
プロジェクトマネジメントは難易度のバラつきが激しいイメージです。めちゃくちゃ簡単な時もあれば、解くのにすごく時間を取られるときもあるような問題でした。
ただ、新しいことを覚えなくても、問題文をしっかりと理解できれば解けるので、そういった意味ではオススメです。
経営戦略・企業と法務
こちらは「ソフトウェア・ハードウェア」の次にオススメの問題だと思います。午前試験の対策をしていれば、問題ないのがやはりいいですね。
あとは「プロジェクトマネジメント」同様、新しいことをいちいち覚えなくていいのもオススメポイントの1つです。
以上、問2~5の選択問題についてでした。
とにかく言えることは、自分に合った問題を見つけましょう!ということです。
まずは過去問を解いてみてください。
あとは、問題文をしっかり読みましょう!これも重要です。
午後試験全体に言えることですが、問題文をしっかりと呼んで理解できれば、そこまで難しくありません。
問題文は流し読みせず、きっちり理解する癖を、過去問を解く段階でつけておきましょう。
(時間配分には気を付けてくださいね。)
問6
問6は「データ構造及びアルゴリズム」です。こちらも必須回答問題なので必ず過去問は解いておきましょう。これは絶対過去問で対策しておかないとダメです。初見だと解けないと思います。
過去問を何問か解いていれば、傾向が見えてくるはずです。
ちなみに慣れれば簡単です。
問題の傾向がほとんど一緒なので、慣れるまでは過去問を解き続けましょう。
問7~11
問7~11は選択問題ですね。1問選択して回答します。こちらは、プログラミング言語で詳しいものがあればそれを選択してもらえればいいのかなと思います。
pythonとか、Javaとか、C言語とか、仕事や大学で使っているものがあれば、それを選択してもらうのが一番なのかなと思います。
私は特定のプログラミング言語を使っていたわけではなかったので、一番簡単と言われている「表計算」を選びました。
私のように経験が無い方は「表計算」を選ぶのが試験合格の一番の近道だと思います。
さて、ではなぜ「表計算」がオススメなのでしょうか??
それは、「表計算」で再頻出の必須関数6種類を覚えるだけで、簡単に高得点を狙えるからです。
新しく覚えなくちゃいけないことがめちゃくちゃ少ないので圧倒的にオススメですね。
以前私も記事にまとめましたので、是非とも活用してもらえれば嬉しいです!
(我ながらキッチリまとめられたと自信があるので、お役に立てると思います。)
この必須関数だけ覚えれば、あとは過去問を解くだけですね。
問題の傾向もつかみやすいので、しっかり対策はしておきましょう。
ここからは余談ですが、もっとキッチリと「表計算」を勉強したい方は、「VBA」??を勉強すればいいんですかね??要はエクセルのマクロです。
私はそこまでやりませんでしたが、試験合格だけでなく、しっかりと知識を身に着けたい方は是非とも参考にしてみてください。
最後に
今回は基本情報技術者試験に合格したので、私が実際にやっていた対策などをまとめました。何度も言っていますが、まずは過去問を解きまくりましょう。
ぶっちゃけ過去問さえ解いていれば、そこまで特別な対策は必要ないと思います。それくらい過去問は重要です。
あとは、しっかりと知識をアウトプットしましょう。
私は勉強した内容を記事としてアウトプットしていましたが、これをやるのとやらないのとでは、知識の定着具合がまるで違いました。
実際に記事を書いた内容については全く忘れていません。
以上、私が実際に基本情報対策としてやっていたことを紹介しました。
私がまとめた記事をすぐに見返せるよう、まとめてもいるので、よろしければそちらも活用してもらえると嬉しいです!
しっかり対策をして、皆さんも試験合格を目指しましょう!
Follow @nlab_notebook
試験直前に見返そう!基本情報対策記事まとめ5選 part3【備忘録-基本情報技術者試験対策-まとめ #3】

少しでも参考になれば嬉しいです。
はじめに
今回は基本情報技術者試験の直前、付け焼刃的に見返せるよう、これまでまとめた記事をピックアップしておきます。試験前にしっかりと対策をしておくことが最も重要ですが、最後に付け焼刃として、試験前日の夜寝る前、試験会場へ向かう電車の中などで見返すように役立ててもらえれば嬉しいです!
リンク
ちなみに私はこの参考書を使って勉強してました。
漫画形式で読みやすく、分かりやすい内容になっているため、無理なく学習を進められると思います。
過去問を解きまくり、不明点があれば参考書で知識を補う、このサイクルで試験対策するのが私のオススメです!
記事まとめ5選 part3
表計算で問われる必須関数6種
基本情報の午後試験、表計算で必ず覚えておかないといけない必須関数6種類をまとめた記事になります。これだけ覚えておけば、表計算は満点取れます。間違いないです。
ディジタル署名を覚えよう!
データ改ざんを防ぐためのディジタル署名についてまとめた記事になります。図でイメージしやすくしているので、是非読んでもらえると嬉しいです。
投機実行って何??
CPUの投機実行が何かについてまとめた記事になります。名前だけだとイメージしにくいのでまとめました。
ディジタル化手順を覚えよう!
アナログ波形データのディジタル化手順をまとめた記事になります。こちらも図でイメージしやすくしています。
3層クライアントサーバシステムって何??
3層クライアントサーバシステムが何かについてまとめた記事になります。他にも、シンクライアントや2層クライアントサーバシステムについてもまとめています。
最後に
さて、今回は、試験直前に付け焼刃として見返せるよう、これまでまとめた記事をピックアップしました。
冒頭にも言いましたが、本来は試験前にしっかりと対策をしておくことが重要です。
その上で、最後試験会場に向かう途中、暇で暇でしょうがなかったら見返してください。
そんなときにふと、抜けていたり曖昧になっていたりする知識を補える手助けになれれば嬉しいです。
目指せ試験合格!
前回まとめた記事も読んでもらえると嬉しいです!
Follow @nlab_notebook
統計学入門⑪ 変動係数
(はじめに)
今まであまり計算では文字式を使わないようにしてきましたが、計算が複雑になってきたので使う場合が増えてくると思います。今更ではありますが、データの変数は$\ x\ $や$\ y\ $、平均値は$\ \bar{x}\ $, $\ \bar{y}\ $、標準偏差は$\ s_{x}\ $, $\ s_{y}\ $、分散は$\ {s_{x}}^2\ $, $\ {s_{y}}^2\ $、共分散は$\ s_{xy}\ $、相関係数は$\ r\ $を使っていきます。その他、新しく出てくるものは都度紹介します。
前回は相関係数の求め方をまとめました。
今回は 変動係数 $CV$ について簡単に学びます。変数を$x$とするとき変動係数$CV$は以下の式で求めます。
$
変動係数\ CV= \cfrac{標準偏差\ s}{平均値\ \bar{x}}
$
標準偏差ってなんだっけ?と思われた方は以下の記事をご覧いただければ嬉しいです。
それでは変動係数について具体例を交えて考えていきます。
変動係数はデータの散らばりを見る際に使います。標準偏差もデータの散らばりを見る際に使いますが、2つのデータを比較する際には注意が必要です。一方で変動係数は2つのデータの散らばり具合を比較する際に使いやすいです。例えば、A社とB社それぞれが販売するマンゴスチン1個の重さの標準偏差と変動係数でデータの散らばりを考えてみます。
A社では平均値$\ $100$\ $g、標準偏差$\ $50$\ $gで、B社では平均値$\ $5000$\ $g、標準偏差$\ $500$\ $gとしましょう。これらを比較すると、B社の標準偏差が大きいので、B社の方がデータの散らばりが大きいように見えてしまうかもしれません。しかし、単純に考えると、平均値が$\ $100$\ $gに対して標準偏差が$\ $50$\ $gであるA社の方がデータの散らばりが大きいように思えます。つまり、このような極端に値が異なる2つのデータの散らばり具合を標準偏差で比較することは難しいということになります。
そこで変動係数を求めてみましょう。A社は0.5、B社は0.1となります。つまりA社の方が散らばり具合が大きいということになります。
以上の例の他にも、単位が異なる2つのデータ(例えば身長と体重)の散らばり具合を比較する際にも使うこともできます。
それでは、問題を解いていきます。
男子高校生30人の身長と体重に関するデータを集めたところ、身長の平均値は$\ $170$\ $cm、標準偏差は$\ $6$\ $cmで、体重の平均値は$\ $60$\ $kg、標準偏差は$\ $9$\ $kgでした。
このとき、身長と体重どちらのデータの散らばりが大きいでしょうか。
ちなみにですが、私はこちらの参考書で勉強しています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
今まであまり計算では文字式を使わないようにしてきましたが、計算が複雑になってきたので使う場合が増えてくると思います。今更ではありますが、データの変数は$\ x\ $や$\ y\ $、平均値は$\ \bar{x}\ $, $\ \bar{y}\ $、標準偏差は$\ s_{x}\ $, $\ s_{y}\ $、分散は$\ {s_{x}}^2\ $, $\ {s_{y}}^2\ $、共分散は$\ s_{xy}\ $、相関係数は$\ r\ $を使っていきます。その他、新しく出てくるものは都度紹介します。
前回は相関係数の求め方をまとめました。
今回は 変動係数 $CV$ について簡単に学びます。変数を$x$とするとき変動係数$CV$は以下の式で求めます。
標準偏差ってなんだっけ?と思われた方は以下の記事をご覧いただければ嬉しいです。
それでは変動係数について具体例を交えて考えていきます。
変動係数はデータの散らばりを見る際に使います。標準偏差もデータの散らばりを見る際に使いますが、2つのデータを比較する際には注意が必要です。一方で変動係数は2つのデータの散らばり具合を比較する際に使いやすいです。例えば、A社とB社それぞれが販売するマンゴスチン1個の重さの標準偏差と変動係数でデータの散らばりを考えてみます。

A社では平均値$\ $100$\ $g、標準偏差$\ $50$\ $gで、B社では平均値$\ $5000$\ $g、標準偏差$\ $500$\ $gとしましょう。これらを比較すると、B社の標準偏差が大きいので、B社の方がデータの散らばりが大きいように見えてしまうかもしれません。しかし、単純に考えると、平均値が$\ $100$\ $gに対して標準偏差が$\ $50$\ $gであるA社の方がデータの散らばりが大きいように思えます。つまり、このような極端に値が異なる2つのデータの散らばり具合を標準偏差で比較することは難しいということになります。
そこで変動係数を求めてみましょう。A社は0.5、B社は0.1となります。つまりA社の方が散らばり具合が大きいということになります。
以上の例の他にも、単位が異なる2つのデータ(例えば身長と体重)の散らばり具合を比較する際にも使うこともできます。
それでは、問題を解いていきます。
Exercise1-10
男子高校生30人の身長と体重に関するデータを集めたところ、身長の平均値は$\ $170$\ $cm、標準偏差は$\ $6$\ $cmで、体重の平均値は$\ $60$\ $kg、標準偏差は$\ $9$\ $kgでした。
このとき、身長と体重どちらのデータの散らばりが大きいでしょうか。
ちなみにですが、私はこちらの参考書で勉強しています。
リンク
リンク
※Amazonのアソシエイトとして、当メディア(Nラボ備忘録)は適格販売により収入を得ています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
シンクライアントシステムと3層クライアントサーバシステムの特徴まとめ【備忘録-基本情報技術者試験対策 #15】

少しでも参考になれば嬉しいです。
はじめに
今回は、シンクライアントシステムと3層クライアントサーバシステムについてまとめます。これらは、コンピュータの動作・処理形態を表したものになります。
複数のコンピュータ同士をどのように組み合わせて動作させるか、というお話ですね。
中でも今回取り上げるクライアントサーバシステムとは、現在主流となっている動作形態であり、これまで使われていた集中処理や分散処理の良いとこ取りをしたような形態になります。
そして、これらクライアントサーバシステムを理解するために必要な考え方が、シンクライアントになります。
ですのでまずは、シンクライアントとは何??というところからしっかりと理解していきましょう。
リンク
ちなみに私はこの参考書を使って勉強してました。
漫画形式で読みやすく、分かりやすい内容になっているため、無理なく学習を進められると思います。
過去問を解きまくり、不明点があれば参考書で知識を補う、このサイクルで試験対策するのが私のオススメです!
シンクライアントシステムって何??
さて、まずはシンクライアントシステムって何??というところからお話していきます。ここで言う「シン」とは、「Thin:薄い、希薄な」というような意味合いで用いられています。
クライアント側の担当する箇所が希薄であり、ほとんどのタスクをサーバ側に任せているというわけです。
クライアント側は何もしませんよ〜ってことですね。
3層クライアントサーバシステムって何??
そもそもクライアントサーバシステムって??
さて、ここから3層クライアントサーバシステムについてまとめていくわけですが、そもそもクライアントサーバシステムが何なのか分からないと、理解しにくいですよね。クライアントサーバシステムとは、クライアント(サービスを利用する側のコンピュータ)とサーバ(サービスを提供する側のコンピュータ)が相互にやり取りをしながら動作するシステムです。
従来のクライアントサーバシステムは2層クライアントサーバシステムと呼ばれ、役割が2層に分割されています。
ひとまずは、
クライアントサーバシステム = 2層クライアントサーバシステム
と考えていいでしょう。
さて、2層クライアントサーバシステムは以下のような階層で特徴づけられます。

図の通り、「プレゼンテーション層」と「アプリケーション層」が2つ合わせて1層となって、クライアント側に存在し、「データ層」はサーバ側に存在します。
ところで、それぞれの階層が担う役割は以下の通りです。
- プレゼンテーション層
ユーザーインターフェースなどの入出力 - アプリケーション層
様々な処理の実施 - データ層
データの管理
すなわち、2層クライアントサーバシステムは、クライアント側でユーザーインターフェースとロジック等の処理を担い、サーバ側でデータ管理を担っているわけです。
いくつか問題点もピックアップしておきます。
例えば、何かしらの処理に変更をかける場合、アプリケーション層がクライアント側にあるため、全てのクライアントに修正をかける必要があります。
他にも、処理に必要なデータをサーバ側に流す必要があるため、その分データが大きくなり、ネットワーク上を圧迫する原因になります。
以上が2層クライアントサーバシステムの特徴になります。
では、今回の本題である3層クライアントサーバシステムはどのような特徴があるのでしょう。
3層クライアントサーバシステム
3層クライアントサーバシステムとは、2層クライアントサーバシステムのクライアント側、「プレゼンテーション層」と「アプリケーション層」を分割し、「アプリケーション層」をサーバ側に置いた状態での動作形態をさします。
クライアント側にあるのは「プレゼンテーション層」のみであるため、入出力の役割だけ担っていればOKです。
これがシンクライアントですね。
サーバ側には「アプリケーション層」と「データ層」がそれぞれあります。
ロジックに変更があった場合でも、サーバ側のアプリケーション層をいじるだけで済むので、クライアント側をいじる必要はいっさいありません。
また、ネットワーク上を流れるデータは入出力の結果のみなので、データがネットワーク上を圧迫することも減るわけです。
最後に・・・
さて、今回はシンクライアントシステム、そして3層クライアントサーバシステムについてまとめました。シンクライアントはそこまで複雑ではないですね。
Point
・シンクライアント
クライアント側はほとんどタスクを担わず、サーバ側に多くを任せている
3層クライアントサーバシステムも、シンクライアントがイメージできていれば難しくないと思います。
Point
以上がシンクライアントシステムと3層クライアントサーバシステムのまとめになります。
しっかり対策をして、皆さんも試験合格を目指しましょう!
前回まとめた記事も読んでもらえると嬉しいです!
Follow @nlab_notebook
統計学入門⑩ 相関係数

今回はより具体的に2つの量的データの相関関係を見るために 相関係数 を求める方法をまとめていきます。
相関係数は以下の式で求めることができます。
標準偏差ってなんだっけ?と思われた方は以下の記事をご覧いただければ嬉しいです。
いきなり出てきた 共分散 は以下の式で求めることができます。
言葉で書くと分かりづらいので、実際に問題を解いてみます。
Exercise1-9
次の量的データ$ x $の標準偏差$ s_{x} $と$ y $の標準偏差$ s_{y} $と共分散$ s_{xy} $ を求めて、相関係数$ r $を求めてみましょう。(データ数が少ないですが・・・)
| $x$ | 40 | 45 | 60 | 65 | 75 |
| $y$ | 55 | 60 | 65 | 70 | 80 |
ちなみにですが、私はこちらの参考書で勉強しています。
リンク
リンク
※Amazonのアソシエイトとして、当メディア(Nラボ備忘録)は適格販売により収入を得ています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
試験直前に見返そう!基本情報対策記事まとめ5選 part2【備忘録-基本情報技術者試験対策-まとめ #2】

少しでも参考になれば嬉しいです。
はじめに
今回は基本情報技術者試験の直前、付け焼刃的に見返せるよう、これまでまとめた記事をピックアップしておきます。試験前にしっかりと対策をしておくことが最も重要ですが、最後に付け焼刃として、試験前日の夜寝る前、試験会場へ向かう電車の中などで役立ててもらえれば嬉しいです!
リンク
ちなみに私はこの参考書を使って勉強してました。
漫画形式で読みやすく、分かりやすい内容になっているため、無理なく学習を進められると思います。
過去問を解きまくり、不明点があれば参考書で知識を補う、このサイクルで試験対策するのが私のオススメです!
記事まとめ5選 part2
フォールトトレラントシステムまとめ
代表的なフォールトトレラントシステムの特徴についてまとめた記事になります。デュアルシステムとデュプレックスシステムの違い
デュアルシステムとデュプレックスシステムの違いについてまとめた記事になります。エンタープライズアーキテクチャと4つの構成要素
エンタープライズアーキテクチャと、それを構成する4つの要素についてまとめた記事になります。「参照呼出し」・「値呼出し」・「名前呼出し」
関数に値を渡すための方法、「参照呼出し」・「値呼出し」・「名前呼出し」についてまとめた記事になります。SMTPとPOP3
SMTPとPOP3の特徴についてまとめた記事になります。最後に
さて、今回は、試験直前に付け焼刃として見返せるよう、これまでまとめた記事をピックアップしました。
冒頭にも言いましたが、本来は試験前にしっかりと対策をしておくことが重要です。
その上で、最後試験会場に向かう途中、暇で暇でしょうがなかったら見返してください。
そんなときにふと、抜けていたり曖昧になっていたりする知識を補える手助けになれれば嬉しいです。
目指せ試験合格!
記事まとめpart1も載せておきます。読んでもらえると嬉しいです!
Follow @nlab_notebook
統計学入門⑨ 散布図と相関関係
今回の内容から2つの量的データの関係について見ていきます。
量的データって何?と思われた方は以下の記事をご覧いただければと思います。 2つの量的データの関係を見るときに便利なものが 散布図 です。
散布図とは、例えば「身長」と「体重」の2つの量的データをそれぞれ横軸(x軸)と縦軸(y軸)として対応させて書いた図のことです。
散布図を使って、2つの量的データの 相関関係 を見ていきます。
・正の相関関係
一方の量的データxが大きくなると、もう一方の量的データyが大きくなるような相関関係を 正の相関関係 といい、下図のように右肩上がりのグラフになります。例えば、身長と体重は一般的に正の相関関係になります。「身長が高い人は体重も大きくなりがち」で、反対に「身長が低い人は体重が小さくなりがち」ということです。正の相関関係
・負の相関関係
正の相関関係とは反対に、xが大きくなると、yが小さくなる相関関係のことを 負の相関関係 といい、下図のように右肩下がりのグラフになります。例えば、最寄り駅からの距離と家賃は一般的に負の相関関係になります。「最寄り駅からの距離が遠くなると家賃は下がりがち」で、反対に「最寄り駅から距離が近くなると家賃は上がりがち」ということです。負の相関関係
・相関関係がない
正の相関関係でも負の相関関係でもなく、xとyに関係がないような場合を 相関関係がない といい、下図のような感じになります。例えば、マンゴスチンを食べた数と50m走の記録といったものがあります。「マンゴスチンをたくさん食べても足の速さに関係ない」ということです。相関関係がない
ちなみにですが、グラフが直線に近いほど"強い相関関係"といい、直線から離れていくと"弱い相関関係"といいます。
それでは次の問題を考えてみます。
次の2つの量的データの相関関係はどうなるか考えてみましょう。
(1)食事量と体重
(2)マンゴスチンを食べた数と物理の定期テストの偏差値
(3)気温とコンビニおでんの売上
ちなみにですが、私はこちらの参考書で勉強しています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
量的データって何?と思われた方は以下の記事をご覧いただければと思います。 2つの量的データの関係を見るときに便利なものが 散布図 です。
散布図とは、例えば「身長」と「体重」の2つの量的データをそれぞれ横軸(x軸)と縦軸(y軸)として対応させて書いた図のことです。
散布図を使って、2つの量的データの 相関関係 を見ていきます。
・正の相関関係
一方の量的データxが大きくなると、もう一方の量的データyが大きくなるような相関関係を 正の相関関係 といい、下図のように右肩上がりのグラフになります。例えば、身長と体重は一般的に正の相関関係になります。「身長が高い人は体重も大きくなりがち」で、反対に「身長が低い人は体重が小さくなりがち」ということです。

・負の相関関係
正の相関関係とは反対に、xが大きくなると、yが小さくなる相関関係のことを 負の相関関係 といい、下図のように右肩下がりのグラフになります。例えば、最寄り駅からの距離と家賃は一般的に負の相関関係になります。「最寄り駅からの距離が遠くなると家賃は下がりがち」で、反対に「最寄り駅から距離が近くなると家賃は上がりがち」ということです。

・相関関係がない
正の相関関係でも負の相関関係でもなく、xとyに関係がないような場合を 相関関係がない といい、下図のような感じになります。例えば、マンゴスチンを食べた数と50m走の記録といったものがあります。「マンゴスチンをたくさん食べても足の速さに関係ない」ということです。

ちなみにですが、グラフが直線に近いほど"強い相関関係"といい、直線から離れていくと"弱い相関関係"といいます。
それでは次の問題を考えてみます。
Exercise1-8
次の2つの量的データの相関関係はどうなるか考えてみましょう。
(1)食事量と体重
(2)マンゴスチンを食べた数と物理の定期テストの偏差値
(3)気温とコンビニおでんの売上
ちなみにですが、私はこちらの参考書で勉強しています。
リンク
リンク
※Amazonのアソシエイトとして、当メディア(Nラボ備忘録)は適格販売により収入を得ています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
試験直前に見返そう!基本情報対策記事まとめ5選 part1【備忘録-基本情報技術者試験対策-まとめ #1】

少しでも参考になれば嬉しいです。
はじめに
今回は基本情報技術者試験の直前、付け焼刃的に見返せるよう、これまでまとめた記事をピックアップしておきます。試験前にしっかりと対策をしておくことが最も重要ですが、最後に付け焼刃として、試験前日の夜寝る前、試験会場へ向かう電車の中などで役立ててもらえれば嬉しいです!
リンク
ちなみに私はこの参考書を使って勉強してました。
漫画形式で読みやすく、分かりやすい内容になっているため、無理なく学習を進められると思います。
過去問を解きまくり、不明点があれば参考書で知識を補う、このサイクルで試験対策するのが私のオススメです!
記事まとめ5選 part1
RAIDの種類と特徴まとめ
RAIDの種類と特徴をまとめた記事になります。「RAID0」、「RAID1」、「RAID5」だけでも最低限覚えておきましょう。
様々な画像処理系の技術まとめ
様々な画像処理系の技術をまとめた記事になります。覚えておくことはたくさんありますが、基本的には名前と内容が一致しています。
丸暗記でなく、名前から連想させるのが良いですね。
「不正アクセス禁止法」と「刑法」の区別
「不正アクセス禁止法」と「刑法」を区別するためのポイントをまとめた記事になります。法律なので、細かいことまで網羅できてはいませんが、基本情報技術者試験で問われる最低限のことだけはまとめています。
「リバースエンジニアリング」・「フォワードエンジニアリング」・「リエンジニアリング」の違い
「リバースエンジニアリング」・「フォワードエンジニアリング」・「リエンジニアリング」の違いについてまとめた記事になります。字面だけ見ると、「リバースエンジニアリング」と「リエンジニアリング」が混同しやすいと思いますので、それぞれの特徴をしっかりと抑えましょう。
「スプーリング」と「スループット」
「スプーリング」と「スループット」についてまとめた記事になります。ただし、覚えることはただ一つ。
「スプーリングはスループットを向上させる。」
です。
最後に
さて、今回は、試験直前に付け焼刃として見返せるよう、これまでまとめた記事をピックアップしました。
冒頭にも言いましたが、本来は試験前にしっかりと対策をしておくことが重要です。
その上で、最後試験会場に向かう途中、暇で暇でしょうがなかったら見返してください。
そんなときにふと、抜けていたり曖昧になっていたりする知識を補える手助けになれれば嬉しいです。
目指せ試験合格!
最後に私の一押し記事も載せておきます。読んでもらえると嬉しいです!
Follow @nlab_notebook
(備忘録-環境・メンタル・好意編)自身の発表に説得力をあげる・理解してもらうためにはpart2
 発表だけでなく、テスト前や面接前などで実力を発揮できないなどと思ったことがある人が大半でしょう。
発表だけでなく、テスト前や面接前などで実力を発揮できないなどと思ったことがある人が大半でしょう。
くわえて、何かを成し遂げる際にどうしたらうまくいきやすいのだろうと考え、メンタルを削りながらやった過去を思い出し、しっかりと考えてみようと至りました。
環境・メンタル編
割と実践していたと気が付いた章。
作業環境の重要性
望ましい目標への連想が、自身の行動の向上に向かうらしい(ここに関してはまだ未実感)
- ゴールに向かうために連想できるものを部屋に配置?
- 顧客や説得相手のことを頭の片隅や物理的に認知させる?
と、良いらしいです。なるべく目標にむかうようなポジティブになれたりする環境が良さそうですね。
説得や試験などの不安要素しかない際の心構え
心構えというものは大事だそうですね…。
不安は成果物の評価を下げ、自信は上げるように、自信というものは大事だそうです。
自分の場合振り返ってみた際、プレゼンや試験等の前々日までにはできることはほとんど終わらせ、前日にはプレゼンなら軽い練習、試験ならちょっと問題を眺めるくらいにして、余裕感をだし、不安を感じそうな行動はせずに、できる箇所だけやっているので自信すらあるかもしれません。たぶん…()。
↓
ただ、テスト前の詰め込みのような、うろ覚えが浮かび上がって不安になるような行動はしないようにしただけです。割と、本番リラックスできます。悟っているだけかもですが。
何はともあれ、不安というのはあまりよろしくないことらしいですね。適度な緊張感は大事だと思いますが。
好感度を上げる・下げない編
使えるかは不明だが、ブログなどの記事や、面接とかの初対面の際に使えそうだなとまとめてみました。
魅力(良いもの・良い雰囲気)は伝播する…らしい
広告が良い例なのですが、有名人が使っているものって、魅力に感じませんか? ↓ 有名人が魅力的であれば、使用しているモノに対しても魅力的に感じる ↓ つまり、有名人とモノという、(広告やSNSで知らなければ)つながりがない2つですが、有名人の魅力と似た魅力がものに対して備わったともいえるのではないでしょうか? ↓ 有名人ではなくても、心地よい画像や美しい画像、楽しそうな画像をすりこむ・ちりばめることで、魅力が備わったモノが出来上がるのではないでしょうか?
こういったものを上手く活用できないんですよね...難しいので。
有利な状態であることを連想させない
(※あまりよくない手法かもしれません…。)
天気が良い日は、気分が良くなっているためか、無意識に良い解答やよい考え方、割と論理的ではない判断(深く考えない)をする可能性が上がるそうです。
しかし、晴れを意識してしまうような連想をさせてしまうと、晴れに意識が向かい、考え方に偏りが無くなるそうです。
これは、アピールしすぎるのと同じで、情報の偏りに気が付いてしまうと。逆に偏りに対して考え方を修正してしまい、意味をなさない、むしろ逆な方向に注意が向いてしまうかもしれません…。
↓
説得や好感度を上げるために使っている手法等は気が付かれないように使うことで、不利にならないで済みそうですね。
類似性というのはすごいらしい
人が似た人を好む=親近感が大事なのは何となく予想が付きますよね。 相手と同じことをするだけでも、良い成果が得られる…らしいです。
- 服装
- 非言語行為(ジェスチャーやポーズ)
- 言語様式(会話で使われる単語や表現の種類)
↓
恋愛の魅力や関係の安定性、敵対的な交渉、ビジネス面でも使える (たがいに気が付いていなくても)らしいです。
↓
類似性が好意に変わりより好意的に互いを評価するようになるそうです。
まとめ
いろいろ学んでみましたが、経験則とは異なることはあんまりなく、ただ、こういった環境や自身、類似性などの重要性を改めて学ぶことができた良い機会でした。活用できたらいいなぁと意識しながら生活してみたいです。
あと、この本で様々な勉強をさせていただきました。この記事の1000倍以上の知識が詰まっています。本当に読んで損のない一冊になっていると思います。
前準備による効果はあると思います。読み物としても面白いので是非読んでみてください。
リンク
こういう本には、専門家が長年研究し積み重ねたものが凝縮されています。それを2日くらいで知識として知れるので、ネットより遥かに良いのでは?と思い始めてしまいました。
※変な本は除く
統計学入門⑧ 代表値(Ⅱ)
以下の記事では平均値、中央値、最頻値の3つの代表値を紹介しました。
3つの代表値の大小関係はデータの分布によって変わります。
今回は、データの分布によって変わる3つの代表値の大小関係について見ていこうと思います。
少し統計学っぽい内容でわくわくします。(そんなことないですかね・・・)
データの分布を3つに分けて見てみます。
面倒臭いので「3分間で1つの学び」が当記事のテーマなので、ここでは具体的な計算はやめておきましょう。
何のこと?と思われた方はぜひ以下の記事もご一読ください。 それでは内容に入っていきます。
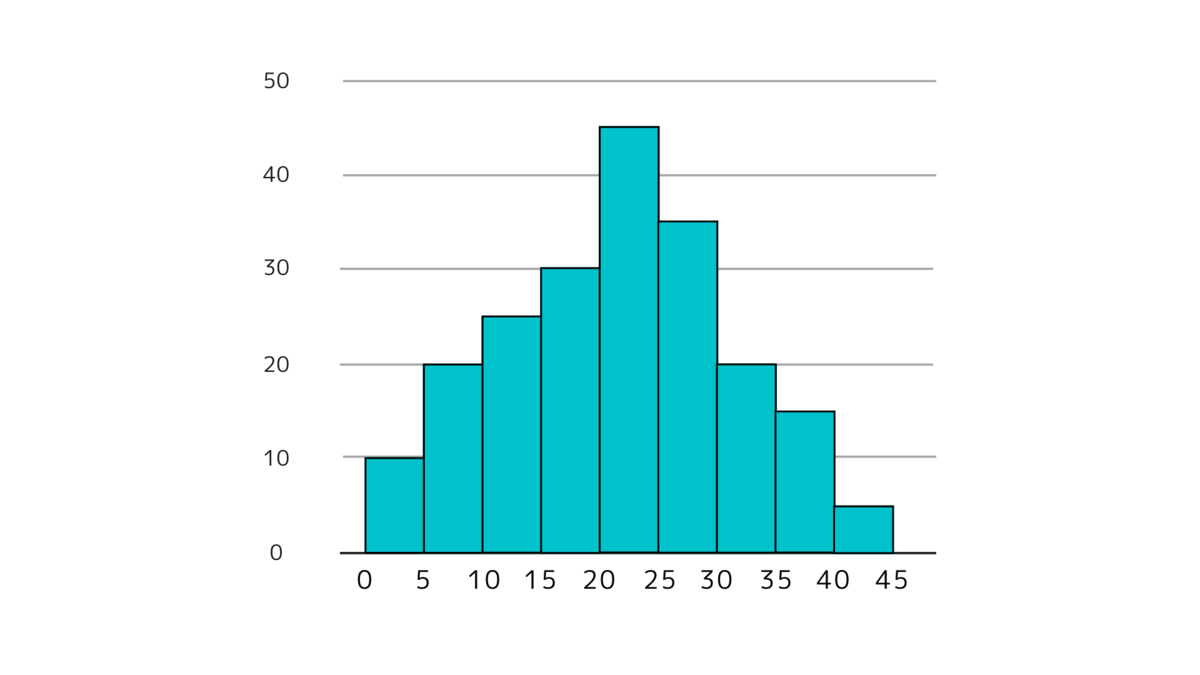
(1)データの分布が左右対称の場合
下図のように左右対称にデータが分布している場合は、
平均値、中央値、最頻値はあまり変わりません。データの分布が左右対称の場合
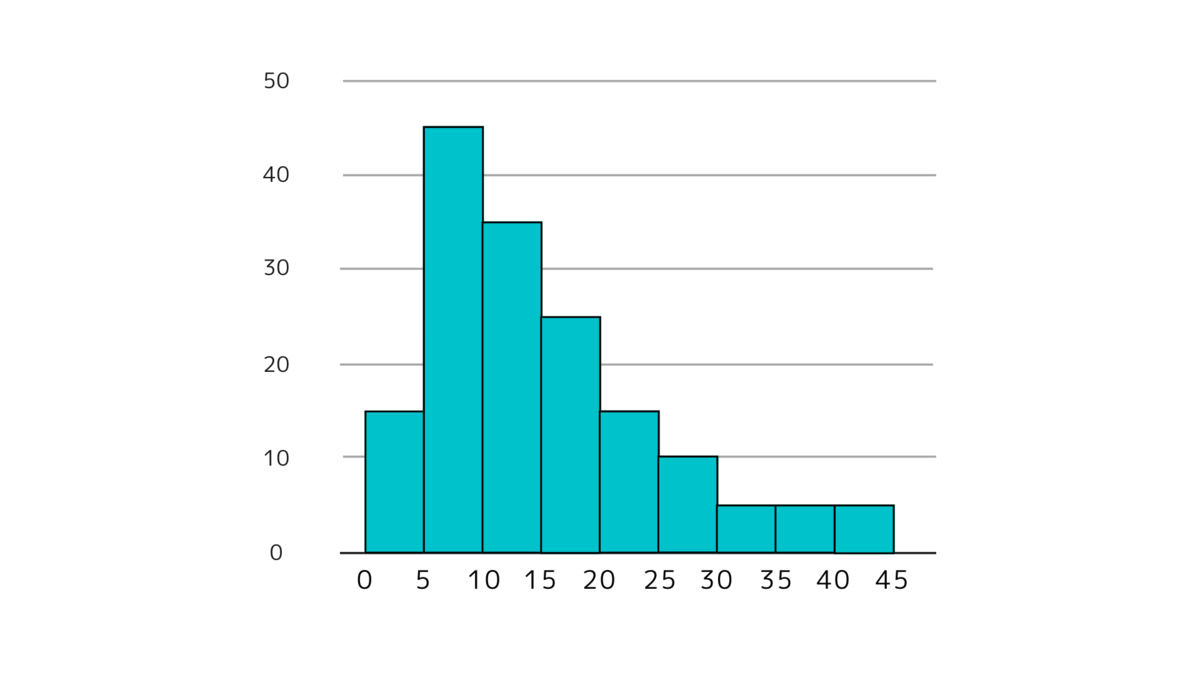
下図のように左に偏ってデータが分布している場合は、
最頻値<中央値<平均値
の大小関係になりやすいです。 (必ずではありません。)
データの分布が左に偏っている場合
(3)データの分布が右に偏っている場合
平均値、中央値、最頻値の大小関係はどのようになりやすいでしょうか。
ちなみにですが、私はこちらの参考書で勉強しています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook
少し統計学っぽい内容でわくわくします。(そんなことないですかね・・・)
データの分布を3つに分けて見てみます。
何のこと?と思われた方はぜひ以下の記事もご一読ください。 それでは内容に入っていきます。
(1)データの分布が左右対称の場合
下図のように左右対称にデータが分布している場合は、
平均値、中央値、最頻値はあまり変わりません。
下図のように左に偏ってデータが分布している場合は、
最頻値<中央値<平均値
の大小関係になりやすいです。 (必ずではありません。)
Exercise1-7
(3)データの分布が右に偏っている場合
平均値、中央値、最頻値の大小関係はどのようになりやすいでしょうか。

ちなみにですが、私はこちらの参考書で勉強しています。
リンク
リンク
※Amazonのアソシエイトとして、当メディア(Nラボ備忘録)は適格販売により収入を得ています。
大したブログではないですが、読者になっていただければ嬉しいです。Twitterも始めているのでフォローよろしくお願いします。
Follow @nlab_notebook